ریسک اعتماد بیش از حد به هوش مصنوعی
هوش مصنوعی اطلاعات خود را از این سایتها میگیرد

یک بررسی تازه نشان میدهد که هوش مصنوعی از برخی وبسایتها به عنوان منابع اصلی اطلاعات خود بیشترین استفاده را داشته است. این رتبهبندی میتواند نشاندهنده میزان اعتماد توسعهدهندگان هوش مصنوعی به منابع مختلف و همچنین تأثیر این وبسایتها در شکلدهی به دادهها و پاسخهای تولیدشده توسط هوش مصنوعی باشد.
براساس تحلیلی که توسط شرکت Semrush انجام شده است، مدلهای زبانی بزرگ (LLM) مانند ChatGPT بیش از همه، به وبسایتهایی مانند Reddit و Wikipedia برای دریافت اطلاعات و حقایق مراجعه میکنند. برای دادههای جغرافیایی نیز، این مدلها معمولاً از دادههای Mapbox و OpenStreetMap استفاده میکنند.
این بررسی، که در ژوئن ۲۰۲۵ و بر اساس بیش از ۱۵۰ هزار اطلاعات استفاده شده توسط مدلهای زبانی بزرگ انجام شد، نشان میدهد که چتباتها تا چه اندازه به محتوای تولید شده توسط کاربران وابسته هستند. این موضوع نگرانیهایی را درباره محدودیتهای ابزارهای هوش مصنوعی امروزی ایجاد کرده است. این رتبهبندی، ارائه شده در قالب یک اینفوگرافیک، نمای روشنی از منابع مورد اعتماد مدلهای هوش مصنوعی ارائه میدهد و به کاربران و توسعهدهندگان کمک میکند تا درک بهتری از عملکرد این فناوریها پیدا کنند.
هوش مصنوعی اطلاعات خود را از کجا میآورد؟
دادههای استفاده شده در این اینفوگرافیک از شرکت Semrush به دست آمده است و نشان میدهد که مدلهای هوش مصنوعی تا چه اندازه به دامنههای مختلف وب هنگام ارائه اطلاعات مراجعه میکنند. این آمار مربوط به ژوئن ۲۰۲۵ است و تصویر روشنی از منابع مورد استناد مدلهای زبانی بزرگ ارائه میدهد.
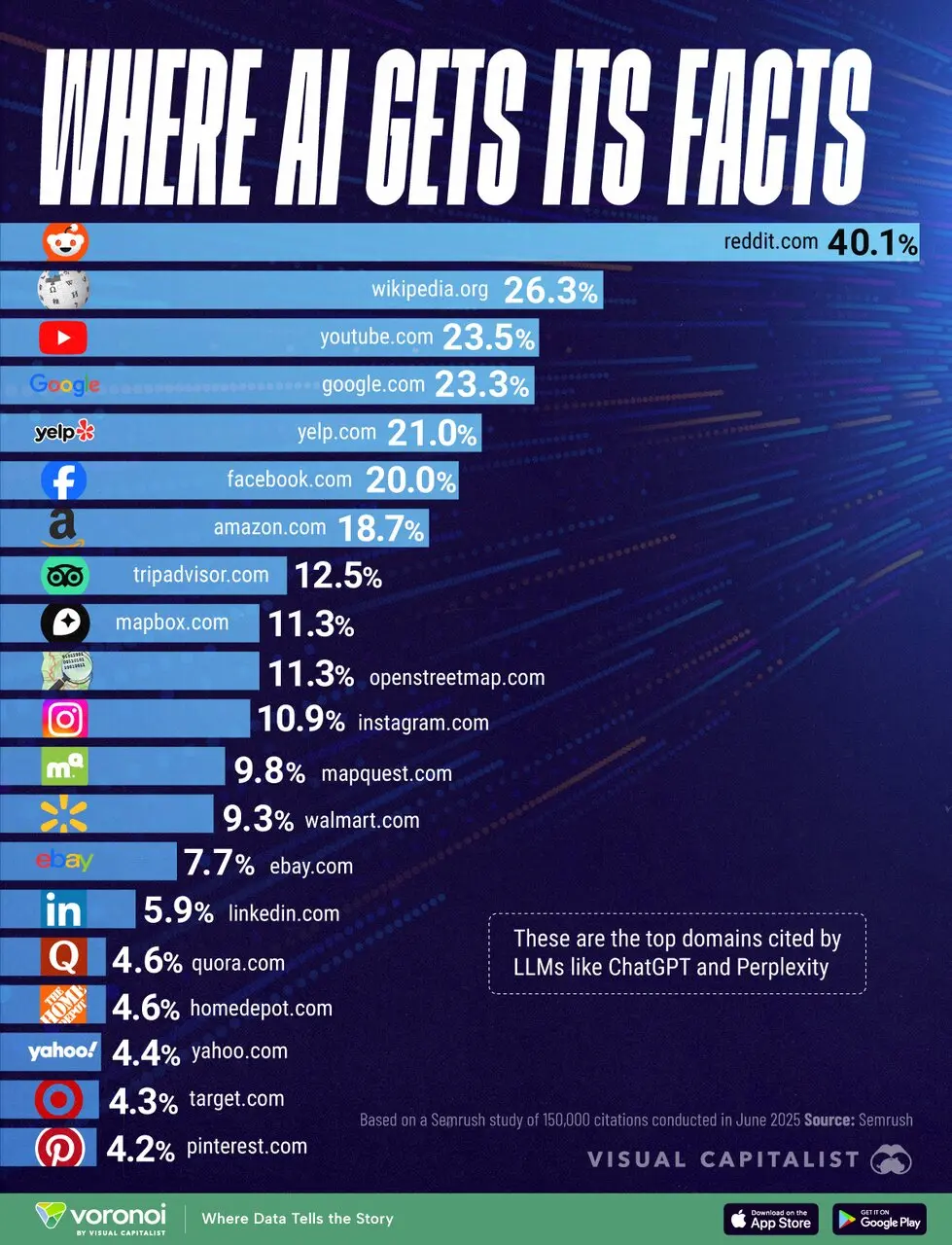
براساس تحلیل ژوئن ۲۰۲۵ از بیش از ۱۵۰ هزار اطلاعات استفاده شده توسط مدلهای زبانی، وبسایتهای زیر به ترتیب بیشترین مراجعه را داشتهاند:
Reddit.com – ۴۰.۱٪
Wikipedia.org – ۲۶.۳٪
YouTube.com – ۲۳.۵٪
Google.com – ۲۳.۳٪
Yelp.com – ۲۱.۰٪
Facebook.com – ۲۰.۰٪
Amazon.com – ۱۸.۷٪
Tripadvisor.com – ۱۲.۵٪
Mapbox.com – ۱۱.۳٪
OpenStreetMap.com – ۱۱.۳٪
Instagram.com – ۱۰.۹٪
Mapquest.com – ۹.۸٪
Walmart.com – ۹.۳٪
eBay.com – ۷.۷٪
LinkedIn.com – ۵.۹٪
Quora.com – ۴.۶٪
Homedepot.com – ۴.۶٪
Yahoo.com – ۴.۴٪
Target.com – ۴.۳٪
Pinterest.com – ۴.۲٪
استفاده از محتوای تولید شده توسط کاربران!
وبسایت Reddit با ۴۰.۱٪ بیشترین میزان استناد و پس از آن Wikipedia با ۲۶.۳٪ در رتبه دوم قرار دارند. این آمار نشان میدهد که مدلهای زبانی بزرگ (LLM) اغلب به بحثهای آزاد در فرومها و محتوای تولید شده و نگهداری شده توسط جامعه کاربران تکیه میکنند.
این وبسایتها منابع گستردهای از دانش تولیدشده توسط کاربران ارائه میدهند، اما ماهیت باز و قابل ویرایش آنها نگرانیهایی درباره صحت و جانبداری اطلاعات ایجاد میکند. وابستگی بالای هوش مصنوعی به چنین منابعی میتواند منجر به تقویت روایتهایی شود که بیشترین دیده شدن یا محبوبیت را دارند اما صحت آنها تایید نشده است. به عنوان مثال، کاربران گزارش دادهاند که ChatGPT گاهی پیشنهاد کرده است که برای تصفیه آب خود از وایتکس استفاده کنند یا آن را با سرکه مخلوط کنند، اقدامی که منجر به تولید گاز سمی کلر میشود.
همچنین باید بدانید که سه ریسک اصلی استفاده از محتوای تولید شده توسط کاربران عبارت است از:
اشاعه اطلاعات نادرست و شایعات: از آنجا که محتوا همیشه توسط کارشناسان دامنه بررسی نمیشود، هوش مصنوعی ممکن است به صورت غیرعمد اطلاعات نادرست یا جانبدارانه را تکرار کند.
تقویت حباب اطلاعاتی: روایتهای محبوب اما تایید نشده ممکن است تکرار شوند و منابع دقیقتر و کمتر دیده شده را تحتالشعاع قرار دهند.
عدم اعتبار: به ویژه در موضوعات حساس مانند سلامت، حقوق و مالیه، وبسایتهای تولید محتوا توسط کاربران فاقد نظارت ویراستاری لازم برای ارائه راهنمایی معتبر هستند.